This document summarizes my goals for the year 2023. The goals themselves are not listed in any particular order, but they are grouped by category. I am doing this for myself. Writing this down forces me to spend a few hours towards the end of the year to reflect on and appreciate everything that I’ve done. As a secondary objective, something here might inspire someone else to follow through on their goals.
Purpose (profession, career, interests)
I don’t believe myself to be predestined to anything, but I want to work on projects that are relevant. I don’t think relevant is strictly the same thing as “good”. In fact, “good” is often an excuse for justifying things that don’t matter. One approach is to be utilitarian: work on things that will have a durable contribution to GDP. I get the most purpose from having goals that help me develop in new ways. If I can see myself evolving across many dimensions and see a path forward, I generally feel purposeful. To put it simply, having things to do, which are also challenging, interesting, and important, gives me purpose.
(score A) Spend at least 100 hours coding/studying ML (aka AI): I built several side projects that made use of LLMs. (1) Tiny Slack GPT is a Slack bot which takes entire conversations as context and can do things like summarizing the viewpoints of different participants in a discussion. It can also assist in a discussion by pulling excerpts from our organization’s documents and database. (2) Promptic is a UI to construct dynamic prompts by selecting options. I made this as an experiment for HeyTutor where we were exploring AI lesson creation. The idea is to select subject, difficulty level, learning style, etc., and feed that to an LLM with zero prompt engineering. (3) I prototyped an LLM-based scraper to extract KPIs (i.e.: ARR, ACV) from notes/transcripts from conversations with founders. (4) I prepared an information-dense presentation that discusses implications of AI for the broader economy and presented it in person at various venues.
(score A) Work with 3 new people I admire: One of the benefits of being an investor at ScOp is getting to work with a portfolio of companies. It also means there are many opportunities to form new professional relationships with people I already know and respect. This year, I was involved in recruiting 4 CTOs: Alex Wilson to Cloverleaf, Phil Gabardo to Lionize, Tumas Rackaitis to Rogo, and David Seigle who I directly hired during my time at HeyTutor. Also at HeyTutor, I had the pleasure to collaborate very closely with Jen Sheffield, now the CEO. Later in the year, I also got to work with my former colleague Heike Schirmer as an executive in residence at ScOp, previously a Director at Amazon Alexa.
(score B) Work more closely with ML companies in portfolio: We have many companies in ScOp’s portfolio doing interesting work in ML/AI, including Yogi, Rogo, Unwrap, Cloverleaf, Customers.ai, and Flip. While I’ve spent a fair amount of time looking at their technology challenges and providing support where possible, I still believe my impact could be higher.
(score A) Write 2 blog posts: I wrote many posts, but LLMs are making writing too easy, so I no longer think this is an important goal. In fact I’ve been thinking about the future of authentic thought leadership. I used to believe that if I had the best ghost writer working for me 24/7, I would be 100x more successful. But now everyone has a great ghost writer. This means that content is no longer trustworthy or valuable. What comes next? So far, I can’t think of many options other than returning to in-person interactions.
(score A) Attend 1 AI conference: NeurIPS
(score F) Complete transaction of Redacted: I thought there was a 50/50 shot at completing a portco transaction in 2023, but it will have to wait. The company is thriving, though, so when the time comes it will be big.
Movies & Miniseries Shows
-------------------------------- --------------------------------
The Fablemans Tulsa King
Oppenheimer Silo
The Menu Barry
Poker Face Fargo (series)
Lessons in Chemistry The Last of Us
Capernaum
The Covenant Audio & Text
The Killer ----------------------------------
Your Honor Founders #311 James Cameron
The Whale Founders #263 and #264 Edwin Land
Living Founders #260 Dee Hock
Daliland Invest like the Best, Palmer Luckey
Armageddon Time Invest like the Best, Patrick Collison
Air (Nike) Invest like the Best, Josh Kushner
All Quiet in the Western Front Invest like the Best, Bessemer
Invest like the Best, Doug Leone
Misc Video How to do Great Work by Paul Graham
-------------------------------- The Brain that Changes Itself
To Be (link #1) Chip Wars
Andrej Karpathy's YouTube A Fermi Paradox Story (link #2)
link #1: To Be
link #2: A Fermi Paradox Story
Connection (partnership, intimacy, family, friends)
I appreciate the meaningful connections that I’ve made throughout my life, including those that were powerful but short lived. Relationships are an important part of life, and I hope my future includes rich experiences with old and new friends. Unfortunately, everyone’s circumstances and interests change, and that means relationships that were once fresh and relevant tend to fall into the background. My observation is that most people allocate significant time and energy to maintain relationships that would otherwise go stale, whereas I’m okay with some relationships dissipating and others flourishing organically. Having a lot of time to myself is extremely important. I enjoy spending most of my weekends diving deep into a new topic, usually tech related, or hiking/running/biking. This creates some tension with maintaining casual relationships, as they usually involve activities in the weekends. Furthermore, casual social activities tend to not start on time and drag on longer than anticipated, which ends up eating into my coveted solo time. I generally prefer social time involving intellectual conversations, shared projects, physical activity, or interesting/new experiences. I believe most people want to separate their personal life (including friends) from work, but for me the ideal friendship is one where there is a high degree of professional intersection. My relationships with family are predicated on the same parameters as other relationships: a history of interactions, common interests, compatible personalities. Fortunately, I was able to find a life partner that shares many of these characteristics. Given that she’s further in the autism spectrum, I’ve been able to reconcile some of these personality traits with my own neurodiversity.
(score A) Greece Trip with Julia: Julia and I had an amazing trip to Greece in the summer. She had taken a classics class and wanted to see and feel the ruins. We rented a car and drove hundreds of miles to visit several ruins. Among other things, I learned that derelict columns are very very important to the Greeks. We walked a ton, ate great food, took a gazillion pictures, and generally strengthened our bond.

(score B) 3 Trips with Friends: I had more than 3 trips with friends, but I also bailed on a backpacking trip in Alaska with Condog, and I had to cancel a mountaineering trip with Dan due to an important work obligation. Even though I don’t regret these decisions, I don’t like being unreliable. It’s one thing to deprioritize casual social events, and an entirely different one to make weak commitments. This is something I need to improve on. Fortunately, I still had the chance to go skiing with many friends in Colo and Mammoth, and spend time in Reno with the Brain Burn crew. I also planned a last minute work trip to NYC with Heike which ended up being great.
(score A) Go to Outside Lands with Julia: This was our second time going to the event together, so now it’s a tradition. Weather was very nice, much less sunny than last year. The most notable moment (a loooong moment) was when we decided to make a front-row attempt during the Foo Fighters performance. We made the call at 2 or 3 pm and fought our way to the absolute best spot, front-center, right by the railings, and watched the performance 8-10 pm. The weather and empty bladders were essential for the success of the mission. Not sure if I would do it again, but it was fun to do it once.
Fitness (strength, endurance, physiology, nutrition)
I feel better when I eat healthy and exercise. Lately, I’ve started to pay attention to my aging and experimenting with methods that can soften the transition, such as being more careful with sun exposure and avoiding products that dry my skin. I’m best at sticking with goals when there are clear KPIs (that move up), so I am an avid user of Strava and do my best to keep a strict fasting schedule.
(score A) Go on 75 runs / 150 miles: 81 runs, 206 miles, 23k ft elevation. I have been less focused on cardio, so I gave myself a relatively easy goal. Most recently, My outdoor running has been negligible. Indoor cardio is just as good, but harder to measure, so I need to find an alternative or pick up my running again.
(score B-) Do Gibraltar 12 times: Gibraltar is a local bike route in Santa Barbara that involves about 4000ft of elevation gain, so this would have been 48k ft. I did about 60 one-third-Gibraltars, totalling 60k ft over 434 miles.
(score B) Pick-up New Workout: I wanted to keep things interesting with a new sport. I considered some edgy candidates such as roller blading but ended up keeping it simple. I started with Yoga in the first half of the year, but then switched to weightlifting, which is sort of cheating because weightlifting was its own goal. But I’ve been very dedicated, spending about 5 hours a week lifting, so there isn’t time for anything else.
(score B) Start Weightlifting: Doing well but started too late in the year.
(score B) Manage Sun Exposure: Mostly doing well except a monstrous sunburn the last day of Burning Man.
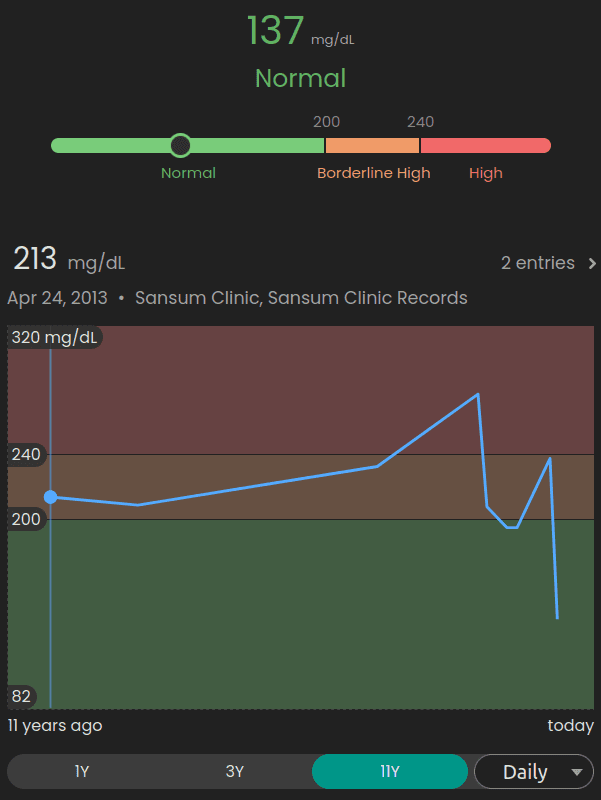
(score A) Lower Cholesterol: Started taking simvastatin. Cholesterol dropped and I’m feeling great– no obvious side effects. Guava shows how I finally dropped total cholesterol after 11 years of tracking it.
Supplements I’m taking
Name Actual Form Quantity
----------- -------------------------------- ----------
Calcium calcium citrate 500 mg
Vitamin D3 cholecalciferol 125 mcg
Vitamin K2 MK-4 100 mcg
Biotin d-Biotin 10 mg
Folate folic acid 800 mcg
Fish Oil D3 as cholecalciferol 25 mcg
Fish Oil omega3 1180 mg
Fish Oil EPA 665 mg
Fish Oil DHA 445 mg
Fish Oil Other 70 mg
Statin Simvastatin 20 mg
NAD+ nicotinamide adeninr dinucleotide 1600 mg
Experience (travel, adventure, surprise, learning)
As I’ve accumulated more experiences, life has become more monotonous. While my past self was concerned (even afraid) of eventual monotony, today I appreciate the opportunity to pursue a continually refined routine. Monotony allows me to eat more healthily, exercise more often, waste less time on things I don’t deem important, and quickly course-correct if I’m disappointed in myself. However, I also believe it is important to be able to look back and quickly recall important/interesting moments. Due to our brain’s ability to constantly improve our pattern recognition, similar experiences are compressed together, becoming hard to recall individually without a relevant queue. On the other hand, novel experiences tend to invade my consciousness even when I’m not seeking them, providing a constant reminder of a life thoroughly lived. To this end, I try to accrue experience outside of my daily routine each year, though with time I’ve realized these infrequent events are also a routine but at a more macro scale (e.g. try to ski each season).
(score B) Ski 14 days: I spent 12 days on the slopes. Other than missing the number of days, it was a great season. I continue to get better at a sport that I encountered only 10 years ago, and which I only get to practice 60 hours a year. The fact that I crashed into a tree and broke a rib or two, doesn’t take away my sense of accomplishment! Last year I was anxious about not getting enough skiing and was considering renting an AirBnB for a month or two, which didn’t happen. Interestingly, this year I don’t have the same craving and have cut down my goal to only 10 days on the slopes. I still hope to do that at some point in the coming years.

(score C) Summer Festival: I enjoy attending an easy summer festival in California every year, usually Lightning in a Bottle, to which I’ve gone several times. These events combine EDM music, with camping, good food, and interactive activities. This year I mistakenly double-booked the same days to go to Greece with Julia, so I gifted the ticket to a colleague. Instead I went for one day to a hyper-local festival in Santa Barbara called Lucidy. I’ve attended Lucidity before, but the weather is not as good (this year was right after an intense rainstorm) and I prefer an environment with fewer people I already know.
(score A) Burning Man: I finally had my glorious return to Black Rock City, with Kevin, Iv, Dario, Chris, Narine, Naz, and some new friends. As usual, this involved a prep weekend in Reno earlier in the season, which was fun by itself. This year was notable in that we had heavy rain during the event and got “stuck”. It looked bad on the cover of the Financial Times of UK, but in reality we were just fine. Burning Man is right at the intersection of doomsday prepping and partying, so we got to have our cake and eat it too. Kevin left early to propose to Aly, so I was left in charge of the Brain Burn and had a blast driving it around the playa.

(score F) Backpacking Trip: This is my biggest disappointment of 2023. Condog delivered a fabulous plan for a backpacking trip, as usual, this time in Alaska. At first, I was very excited, but over the next several weeks I kept getting overwhelmed by the idea. Flights to Alaska suck. Arrivals and departures are in the middle of the night. It was a very rainy season, and I was dreading an infestation of mosquitoes, which Conor exacerbated with a video clip of the inside of his RV being massacred by skitters. There’s fucking bears in Alaska, like real Bears, not the cutesy things you see at Yosemite. I had a trip immediately preceding and immediately after the Alaska trip. And to top it all out, Patricia ended up in the ER for a kidney infection a couple days before I was scheduled to leave. She asked me not to go, and while 90% of the time I would have pushed back, this time I felt relief and cancelled last minute.
(score F) Mountaineering Trip: My good friend Dan Tobin has been trying to get me mountaineering again. This particular trip overlapped with a potential key meeting for a big transaction at work, so I cancelled. Dan is a great guy and I hope we have another adventure together some time. For a while, it seemed like I was going to get into mountaineering. It’s in my personal history, having grown up in the Andes. I’ve done some interesting trips, including Aconcagua, Shasta, Whitney, Dana, Shuksan, and a couple others. But then I slowed down. Maybe risk aversion, maybe I just hate waking up at 2 am for a 12 hour summit push. Not sure. With this sort of thing it’s helpful to have people that are into it. My last father in law, Ray, was awesome at planning trips for Briana and I. My former colleagues Tom and John were good adventure partners, but they are now trying to make it rich and are postponing happiness to another day.
Legacy (children, mentoring, enterprise)
I am fortunate to have my step-daughter Julia in my life, in spite of not having biological children. For people outside of my family, I’ve had the highest impact when contributing to an individual’s professional development. This requires finding people that want to have that kind of relationship, and whose needs are aligned with my strengths. I used to think of this exercise as “mentoring”, but in hindsight I’ve also had impact on peers/friends in addition to mentees. I just enjoy talking about career and personal goals and will do it with anyone that will engage.
(score A) Adopt Julia: I thought it would be a nice gesture to make our relationship official, even if there aren’t practical advantages. The process was very easy. We avoided doing the adoption while she was underage, because even if a kid is 17 and they’ve been living with a step-parent for 5 years, the government will send child services and do the whole ordeal before an adoption is authorized. On the other hand, adopting an adult is trivially easy. So easy, that I suspect you could adopt someone without their knowledge.

(score B) Mentor 3 Young People: I often engage with high-potential young people. Either friends of my daughter, through extended relatives/friends, or people that I meet in colleges or high schools when I give talks. I also have a few educators who know I like to mentor and will introduce me someone from time to time. I am happy with the flow of introductions and I think I’m having a positive impact on each of these meetings. But I’d like to see some of the interactions repeat more than once or twice. I’ve had a few people with whom I met semi-regularly, but it was often me driving it, and when I stopped, it died out. I think good mentorship has to be two sided to become a potentially life-long relationship.
(score A) Be Helpful to th Professional Journey of 3 People : I feel great about this. I believe I was helpful to Alex, David, Phil, and Tumas on their CTO journeys. I helped Deven in his transition from investor analyst to operator. I’d like to think I supported Jen in taking over CEO at HeyTutor. And I hope some of the discussions I had with Heike were as helpful to her as they were for me. In all these cases, I’ve learned/gained just as much or more from my interactions with each of these people.
Misc Photos
More skiing





Snow in Santa Barbara


Flooding in Santa Barbara


I’m great with toddlers…


The Sierras


Dave’s Wedding


ScOp’s offsite

More Family Photos








More Burning Man



Schnurr’s Wedding


Ryan’s Wedding


NYC!


Diego visiting from Israel

]]>